


Learned Upsampling at 60 FPS

Table of Contents
TinySR⌗
Last week I was able to train a cutting-edge fast super-resolution model achieving +5.749 dB PSNR over bicubic baseline: https://catid.io/posts/upsampler/ On a high-end modern GPU, the high quality model can run at video framerates.
However “fast” is relative to where it’s running. On a normal laptop without a discrete GPU, it can only run at 1 FPS on the Intel integrated GPU. This is not fast enough for real-time applications, and probably the same model would not run very fast on cellphones either.
So, instead of using a VapSR network, I looked at the NTIRE 2023 RTSR competition to find a new network design to try. The fastest network is the Bicubic++ model ( https://arxiv.org/pdf/2305.02126.pdf ). There is no code available for this network, so I had to implement it myself.
Somewhat arbitrarily, I decided to design the highest quality super-resolution model that can upsample 960x540->1920x1080 at 60 FPS on the Intel Iris Xe Graphics G7 96EUs at 1400 MHz. This means that probably even the Intel UHD 620 GPU can run at 30 FPS. These results seem like they could be useful for practical real-time applications.
The code for my model is at https://github.com/catid/upsampling in the tiny branch: https://github.com/catid/upsampling/blob/tiny/tiny_net.py
Example⌗
Top-Left: Original Image. Top-Right: Tiny model output.

Bottom-Left: Input Image. Bottom-Right: Baseline Bicubic upsampler.
If you compare this to the previous large network output, it looks about 2x worse, but still much better than normal bicubic upsampling.
Design⌗
BatchNorms, biases and other such tools to train deeper networks are not necessary for tiny models. It’s clear from existing literature that these operations are often harmful for quality at a given level of performance.
Using ReLU instead of GELU or LReLU activation is a good idea for tiny models since ReLU is implemented with max(x, 0) that is very fast on all targets. Adding a ReLU operation uses almost no additional time in my testing, so it’s a good idea to use as many as needed so the model can learn more complex functions.
One optimization that’s common is replacing expensive full conv2d 3x3 with a separable convolution that first acts on the each channel separately with a depth-wise conv2d 3x3, followed by a point-wise conv2d 1x1. I found that this reduces quality imperceptibly, but greatly reduces the number of parameters. OpenVINO does not reward us with faster execution time however, and in fact runs slightly slower. I’m gaining the intuition that number of layers is more important than number of parameters for OpenVINO perhaps due to slow memory access time between layers. However, I feel like the reduced number of parameters was an improvement overall.
After training and conversion to ONNX, using Netron to visualize the model was very helpful to verify that it was doing what I expected. Furthermore, openvino-workbench has a model visualizer for the .bin/.xml OpenVINO IR model, which is useful to check what operations might need to be improved for performance.
For example, I found that the bias terms in conv2d layers was creating a separate add operation in the OpenVINO IR model which led to poor cache usage and a big performance hit. Removing the bias terms also just happens to improve performance of the model, so it’s a win-win.
Implementing a space-to-depth operation in PyTorch does not convert well to OpenVINO:
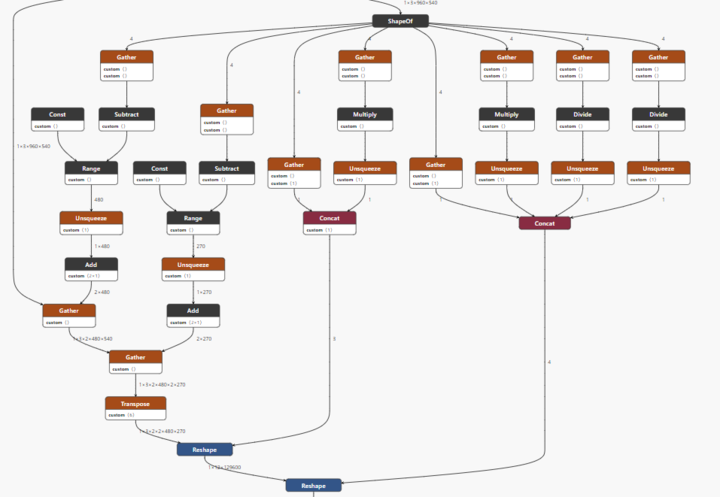
This space-to-depth operation is an important performance feature of the Bicubic++ model. What makes the Bicubic++ model special is that it immediately downsamples the - already downsampled - input image by 2x, so that the body of the network runs significantly faster than alternative designs. So, this space-to-depth operation needed to be improved.
I made the somewhat unusual decision to put the work of changing the tensor layout on the CPU. This seems fine because the CPU was already converting from NHWC to NCHW layout, so it’s not a big deal to add a space-to-depth operation to that, which just shuffles the color from 2x2 pixels into the color channel dimension, so there are 12 channels instead of 3. Down the line this can be done efficiently with SIMD shuffle instructions, so it’s not a big deal to do it on the CPU.
At these small sizes, input normalization is expensive, so I’m performing that inside the model on the GPU. The model also converts back to 8-bit at the end. Advantages:
- Reduces CPU-GPU bandwidth by 2x for FP16 models to and from the GPU.
- Speeds up inference by using much faster GPU FP16 operations for normalization.
- Reduces the chance that training and inference are different due to slightly different normalization calculation.
- Simplifies the data loader in the training script.
It was trained over 14 hours (about 25K epochs) on the same cluster of 8x RTX4090s used in the previous post until validation loss stopped improving for 1000 epochs. The dataset was different from the previous model, including DIV2K training and valdiation sets, Flickr2K, KODAK, and Sunhays80. I used 2% of the data for measuring validation loss during training for a noticeably smoother validation curve. Each epoch took about 1.92 seconds. It was mostly CPU limited since most of the time was spent loading the dataset and the tiny model itself trained fast on GPU. Probably a threadripper-type machine is better suited to training these models, but it still runs very fast.
Tiny Super-Resolution Model⌗
Model shape and parameter count is pretty similar to other tiny super-resolution models:
Name: conv1.0.weight, Type: torch.float16, Size: torch.Size([32, 12, 3, 3])
Name: body.0.rb.0.weight, Type: torch.float16, Size: torch.Size([32, 1, 3, 3])
Name: body.0.rb.1.weight, Type: torch.float16, Size: torch.Size([32, 32, 1, 1])
Name: body.0.rb.3.weight, Type: torch.float16, Size: torch.Size([32, 1, 3, 3])
Name: body.0.rb.4.weight, Type: torch.float16, Size: torch.Size([32, 32, 1, 1])
Name: body.0.skip_mix.0.weight, Type: torch.float16, Size: torch.Size([32, 64, 1, 1])
Name: d2s.0.weight, Type: torch.float16, Size: torch.Size([64, 32, 3, 3])
Name: d2s.3.weight, Type: torch.float16, Size: torch.Size([12, 16, 3, 3])
Total number of parameters: 28288
On the Urban100 test set, it achieves 1.788 dB higher PSNR than bicubic, and 4x lower LPIPS (human perception) loss. So, perceptually it’s much better.
2023-05-22 06:16:50,945 [INFO] Model PSNR: 26.65966205330651 - Bicubic PSNR: 24.87192185623686
2023-05-22 06:16:50,945 [INFO] Model SSIM: 0.8725496033554337 - Bicubic SSIM: 0.8233347716777945
2023-05-22 06:16:50,945 [INFO] Model LPIPS: 0.00033572075771443706 - Bicubic LPIPS: 0.0013645301913965267
With a batch size of 1 image, OpenVINO inference processes images from 960x540 -> 1920x1080 in 15.461 milliseconds per frame, which is faster than 60 FPS. I was testing with Python so with a good C++ framework this would be faster. Also it’s using RGB input, so it’s not quite representative of real-world performance where YUV 4:2:0 would be used and you’d expect faster speed and higher quality.
This super-resolution model is small enough that it can be visualized in a single image. The OpenVINO IR model graph is on the left, and the input ONNX graph is on the right. Notice how they are identical since the model has been designed to avoid any extra operations when converting to OpenVINO IR.
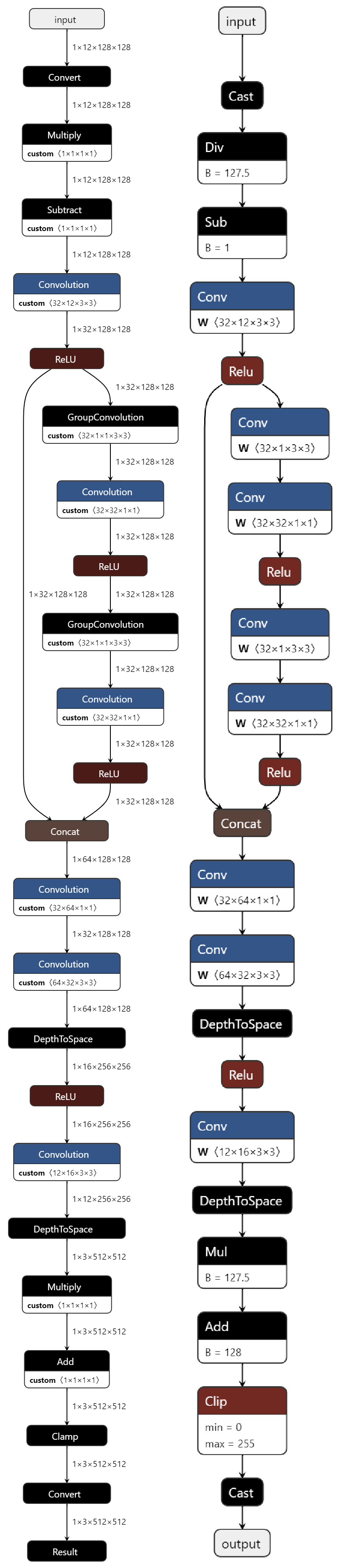
The initial Cast/Div/Sub are normalization. Then there’s a 2x downsampling + feature extraction conversion from 2x2 3-channel RGB pixels (12 channels) to half-sized resolution tensors with 32 feature channels.
The main part of the network looks like a single residual block with two separable convolutions separated by ReLU. I went back to the original ResNet and Highway Networks papers to understand this design choice. It turns out there are lots of minor variations that might work better. One interesting variation for small networks is using a convolution to mix the skip connection with the main path, which performs better when networks are smaller based on these classic papers.
In my variations of Bicubic++ I concatenate the residual block with the skip connection and perform a 1x1 convolution to mix them. I’ve seen this sort of concatenated mixing in other super-resolution network designs from the NTIRE competition. I found these extra parameters help the network learn more interesting features. It sort of looks like an attention network used by VapSR, since the residual block has a larger receptive field than the initial 3x3 features and it has the chance to gate the skip connection, but it could also learn other types of mixing so it seems very expressive for just a little extra cost. Since it’s replacing an add layer at quarter resolution in the OpenVINO graph, the performance hit from a heavier operation is somewhat offset and only adds about 1 millisecond to the inference time. I tried adding a ReLU after the new mixing convolution, which reduced output quality by 0.1 dB PSNR.
The final part of the network is a 4x upsampler, which converts 32 channels at quarter resolution to 16 channels at half resolution. And then from 16 channels at half resolution to 3 channels at full resolution. The final Mul/Add/Clip/Cast are de-normalization and conversion to 8-bit RGB in NCHW layout.
Variations of Bicubic Downsampling-then-Upsampling⌗
I’m comparing using the same set of cropped Urban100 images used to evaluate my model, with the image_folder_compare.py from my repo.
Using ImageMagick for downsampling, ImageMagick for upsampling:
* convert "$image" -resize 50% -filter Cubic PNG32:"$output_image"
* convert "$image" -resize 200% -filter Cubic PNG32:"$output_image"
Mean PSNR: 24.621472693908935 SSIM: 0.8136691451072693 LPIPS: 0.0015053656451699852
Using PIL for downsampling, PIL for upsampling. This is what is used for my model:
Mean PSNR: 24.8788588684606 SSIM: 0.8237610459327698 LPIPS: 0.0013115047611889266
Using ImageMagick for downsampling, PIL for upsampling:
Mean PSNR: 25.165479554756793 SSIM: 0.8333361744880676 LPIPS: 0.0010422282023494329
Strangely ImageMagick has the best downsampling implementation, and PIL has the best upsampler. The model is trained on PIL downsampling so we use that for the rest of the comparisons. The choice of downsampler is very important, and it motivates learning a better downsampler for future work. I compared the round trips and the differences are around image features not at the borders, so it actually does seem to be a better kernel being used by ImageMagick.
Comparisons with Magic Kernel⌗
In addition to bicubic, we should probably also compare to other fast image processing algorithms, starting with John Costella’s Magic Kernel ( https://johncostella.com/magic/ ). Since his code also implements Lanczos resampling we also compare to his implementation of that ( https://en.wikipedia.org/wiki/Lanczos_resampling ).
Lanczos 2:
Using ./build/opt/bin/resize_image -k 2 -m LANCZOS -a 2 -p "$image" "$output_image"
Mean PSNR: 24.545236070267055 SSIM: 0.8192198872566223 LPIPS: 0.001238669355672329
Lanczos 3:
Using ./build/opt/bin/resize_image -k 2 -m LANCZOS -a 3 -p "$image" "$output_image"
Mean PSNR: 24.791738948832595 SSIM: 0.8266182541847229 LPIPS: 0.0008635188044593691
Magic Kernel:
Using ./build/opt/bin/resize_image -k 2 -m MAGIC_KERNEL -p "$image" "$output_image"
Mean PSNR: 23.044779662495284 SSIM: 0.756813108921051 LPIPS: 0.0024101036172208107
Magic Kernel Sharp:
Using ./build/opt/bin/resize_image -k 2 -m MAGIC_KERNEL_SHARP -p "$image" "$output_image"
Mean PSNR: 24.81309103889301 SSIM: 0.8279603719711304 LPIPS: 0.0009978463711557378
Honestly Magic Kernel looks broken somehow. Its performance is significantly worse than other options. I took image differences and did not see any problems at the image borders so it seems to be a problem with the kernel itself.
Bicubic (repeated from above for clarity):
Mean PSNR: 24.8788588684606 SSIM: 0.8237610459327698 LPIPS: 0.0013115047611889266
These results are not surprising for me, since I’ve already compared some of these options like Lanczos and Bicubic at work considering PSNR, and Bicubic is usually the best option for 2x or 4x downsampling-then-upsampling. However, we do see that perceptually, someone might slightly prefer Magic Kernel Sharp or Lanczos 3 over Bicubic, likely because they emphasize edges better, based on the LPIPS scores.
In general the conclusion here is that a learned upsampler is significantly better than any of these traditional approaches.
Comparison to Nvidia Upsampling SDK⌗
Nvidia has an upsampling SDK that is released here: https://github.com/NVIDIAGameWorks/NVIDIAImageScaling
It compiles cleanly with Visual Studio 2022 on Windows. If you build the DX12 sample, add images under NVIDIAImageScaling\samples\bin\DX12\media\images, run the DX12 sample application, and then select 50% scale and one of the images from the drop-down, you can press the S key to have it save the image to NVIDIAImageScaling\samples\bin\DX12\dump.png.
Since it is laborous to run it on every single image in the test set, I instead just compare 10 representative images from the set, which are the 10 I’ve most looked at over the past few weeks:
frame_img_001_SRF_4_HR_scale1_part0.png
frame_img_003_SRF_4_HR_scale1_part0.png
frame_img_007_SRF_4_HR_scale1_part0.png
frame_img_008_SRF_4_HR_scale1_part0.png
frame_img_017_SRF_4_HR_scale1_part0.png
frame_img_020_SRF_4_HR_scale1_part1.png
frame_img_024_SRF_4_HR_scale1_part0.png
frame_img_037_SRF_4_HR_scale1_part0.png
frame_img_098_SRF_4_HR_scale1_part0.png
frame_img_100_SRF_4_HR_scale1_part0.png
The results are very poor:
Nvidia Upsampling SDK:
Mean PSNR: 21.493067573018024 SSIM: 0.7309025526046753 LPIPS: 0.0011881895319675096
Model evaluation on just these 10 images:
2023-05-22 20:34:18,117 [INFO] Model PSNR: 25.110283076710758 - Bicubic PSNR: 23.65697940868438
2023-05-22 20:34:18,117 [INFO] Model SSIM: 0.8417805168194482 - Bicubic SSIM: 0.7870789210851086
2023-05-22 20:34:18,117 [INFO] Model LPIPS: 0.000343972205882892 - Bicubic LPIPS: 0.001076263100549113
So, bicubic looks generally more accurate than Nvidia Upsampling SDK on photographic imagery. Meanwhile, the learned upsampler improves on accuracy by +1.45 dB PSNR, and about 3x better LPIPS perceptual score. Bicubic does tend to blur the images a bit more, so I suppose that players would prefer artifically sharpened frames in gaming.
Basically people like a bit of “sharpening” in their images even if it’s not representative of the original image. Honestly I do too, since I prefer “enhanced” mode to “film-maker” mode on my TV. This does make the Nvidia Upsampling SDK a good option for enjoyment of game content, but not for use in a photographic video pipeline.
AMD FSR 1 is considered to be similar in quality to Nvidia Upsampling SDK based on gamer reviews. I built the samples for it with Visual Studio and did not find a way to import/export PNG images to perform a comparison, so I cannot dispute the community consensus.
Learned Upsamplers for Gaming⌗
AMD FSR 2 and Nvidia DLSS lean heavily into motion estimation and other video techniques that are not applicable to still images, so I did not consider them here. I believe the machine learning used in these solutions is tuned for specific games, which would make these not applicable to video.
Note that Nvidia of course has experimented with AI upsamplers, achieving similar results to my model, stating 1-2 dB higher PSNR. See the “AI SUPER REZ” section of this whitepaper: https://images.nvidia.com/aem-dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
They do not state the size or speed of the model they evaluated, so it’s hard to compare. I believe that Nvidia and AMD should consider deeper networks. My VapSR result is significantly higher than 1-2 dB PSNR, and it runs much faster than real-time on an RTX 4090, so it would be an improvement for video upsampling. There are likely some intermediate-sized networks that would be a better tradeoff between quality and speed, traded against time spent rendering games.
Future Work⌗
When working on YUV 4:2:0 images (like JPEG etc), the colorspace is YCbCr instead of RGB. DALI supports this conversion so it’s fairly simple to experiment with. More importantly, the UV channels are at half resolution, so the model needs to be improved to accept UV channels as a separate input. These channels do not need to be downsampled at the start of the network, and do not need as much work to reconstruct at the output. This should lead to a significant improvement in quality and speed once the model is converted to use this smaller input. I’ve seen two papers where YUV 4:4:4 colorspace led to better quality super-resolution results than RGB.
Upsampling by 3x is also interesting since it means the input resolution would be 640x360, which is evenly divided by 8 so is a more natural input resolution for video codecs. It’s possible 3x upsampling could lead to a better overall rate-distortion metric for video compression, so it seems like a good idea to have a 3x model to compare against.
Testing on Intel UHD 620, AMD processors, and on cellphone targets would be useful as next steps for this model to see if it needs to be further optimized for those targets.
The next thing I need to learn how to design is a jointly-learned downsampling network. This would run before the video encoder to improve performance of the upsampler later. I’ve seen 3dB improvements, but probably for tiny models it’s not going to be that much. If I could get 1.5 dB improvements then I’d be incredibly elated. I’m looking at using a differentiable JPEG encoder/decoder to simulate quantization and quality degradation from the traditional video encoder, since differentiable video encoders do not exist in the public domain.